01:00
Causal Inference
Causal Inference
Causal inference is what we do when we identify and estimate the causal effect of some proposed cause on an outcome of interest.

List the Pathways
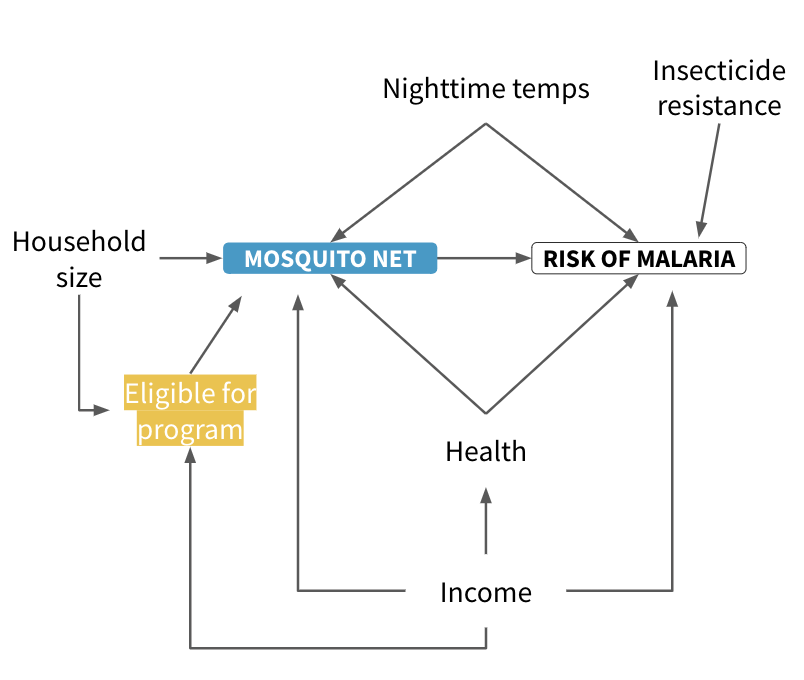
There is a direct path between mosquito net use and the risk of malaria, but the effect is not causally identified due to several other open paths. List all of the paths and find which open paths have arrows pointing backwards into the mosquito net node.
03:00
Paste Code into R
# Load packages
library(dagitty)
# 'content between quotes' pasted from DAGitty.net
mosquito_dag <- dagitty('dag {
bb="0,0,1,1"
"eligible for program" [pos="0.303,0.552"]
"household size" [pos="0.222,0.393"]
"insecticide resistance" [pos="0.623,0.251"]
"mosquito net" [exposure,pos="0.338,0.393"]
"nighttime temps" [pos="0.471,0.273"]
"risk of malaria" [outcome,pos="0.616,0.396"]
health [pos="0.469,0.493"]
income [pos="0.473,0.697"]
"eligible for program" -> "mosquito net"
"household size" -> "eligible for program"
"household size" -> "mosquito net"
"insecticide resistance" -> "risk of malaria"
"mosquito net" -> "risk of malaria"
"nighttime temps" -> "mosquito net"
"nighttime temps" -> "risk of malaria"
health -> "mosquito net"
health -> "risk of malaria"
income -> "eligible for program"
income -> "mosquito net"
income -> "risk of malaria"
income -> health
}'
)
plot(mosquito_dag)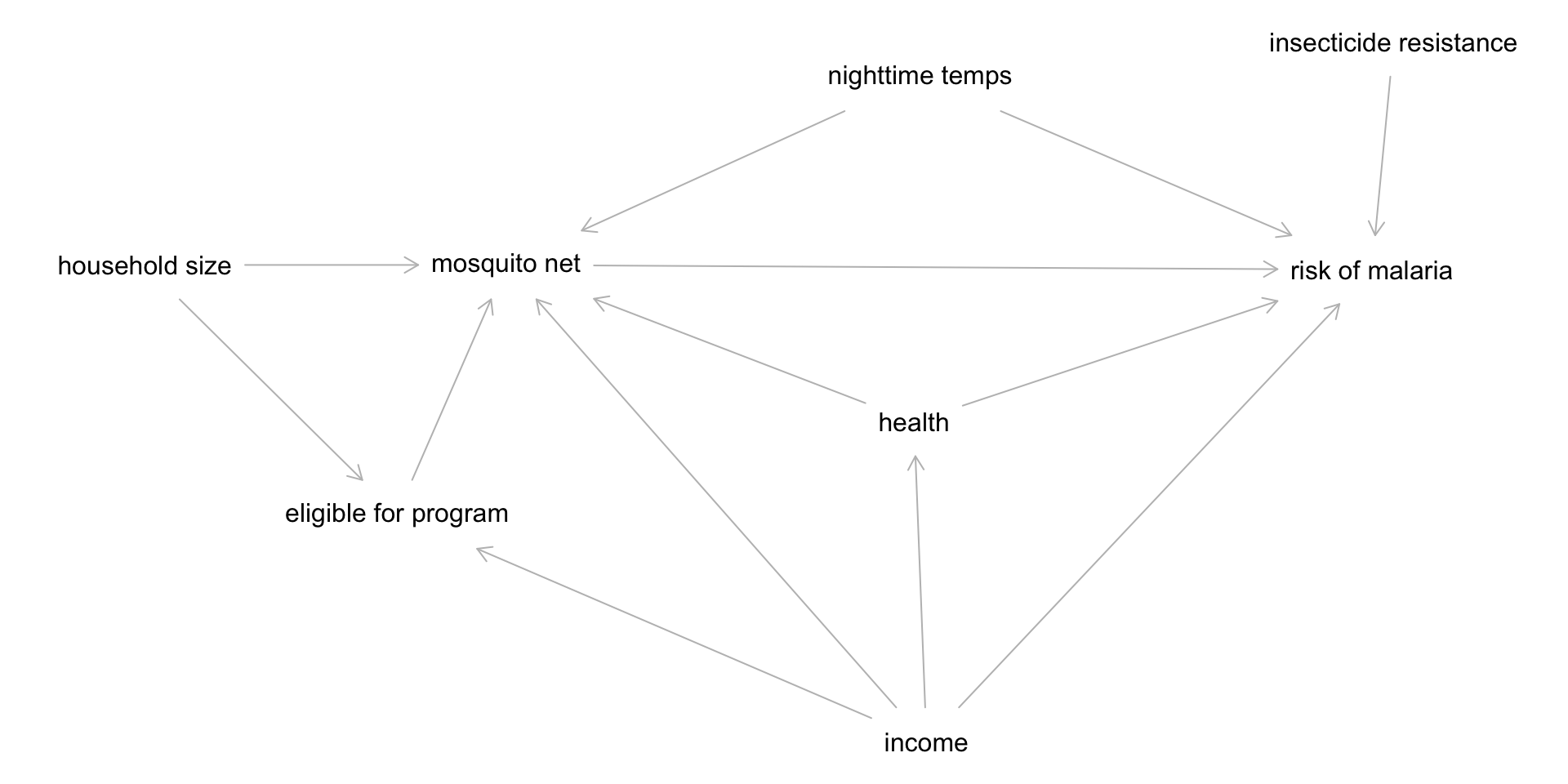
Identify Minimal Adjustment Set
This tells us that we only need to control for health, income, and nighttime temps to identify our causal effect of interest (nets -> malaria risk). We see the same on DAGitty.net.

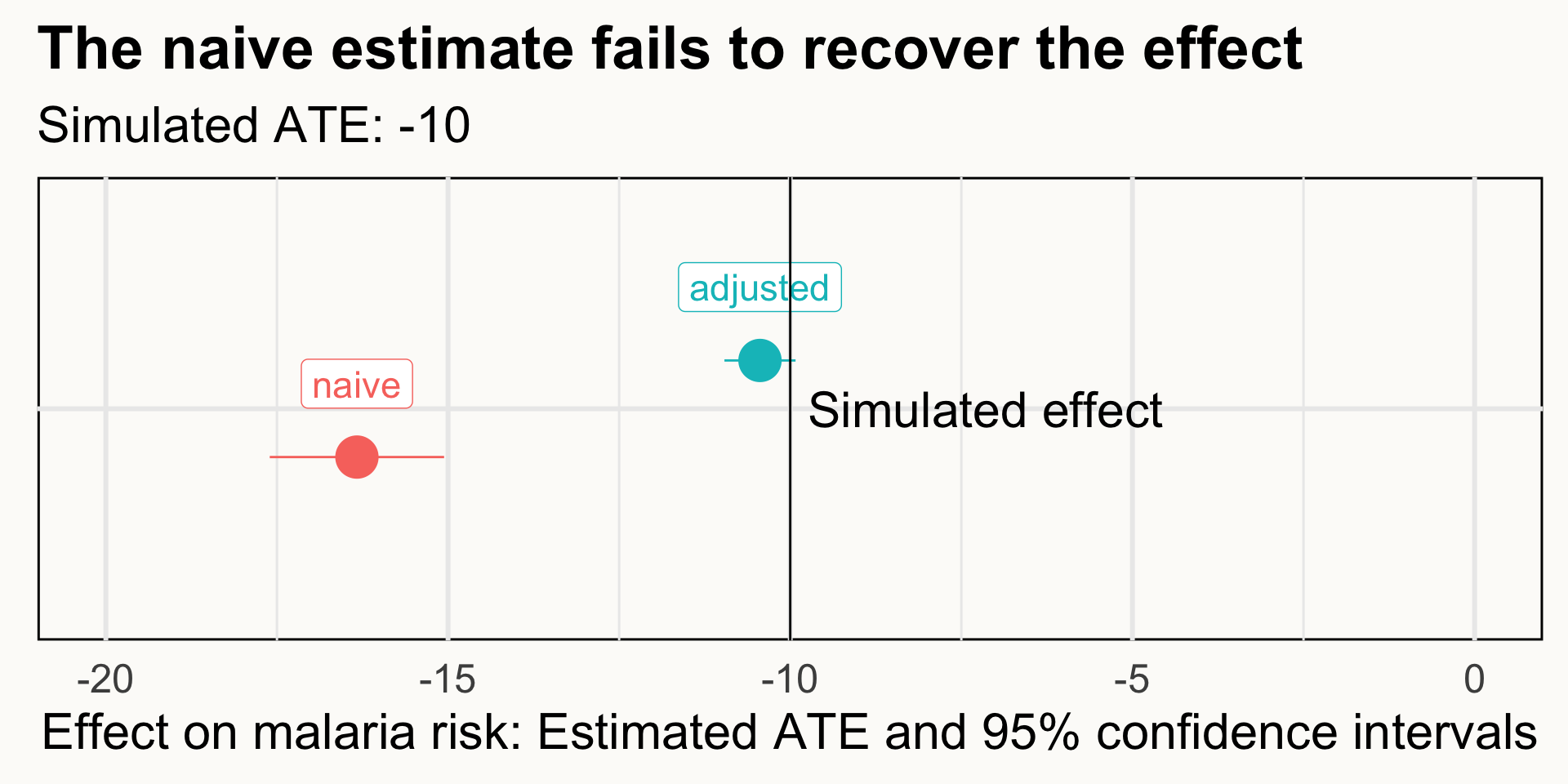
Naive vs Adjusted
library(modelsummary)
library(gt)
model_naive <- lm(malaria_risk ~ net, data = mosquito_nets)
model_adjusted <- lm(malaria_risk ~ net + income + temperature + health,
data = mosquito_nets)
# Heiss's appropriate warning:
# Making confounding adjustments with linear regression will result in properly identified causal relationships only under very specific circumstances.
# See https://www.andrewheiss.com/research/chapters/heiss-causal-inference-2021/10-causal-inference.pdf